Legacy machines run for decades, but tribal knowledge walks out the door. How do you capture expertise before it's gone?
Bruviti deployment data shows AI guided auto-triage on 60% of faults and cuts resolution time by 20 to 30% for industrial equipment field teams. Builders wire fault data, parts logic, and tech-assist into one pipeline so technicians arrive with the diagnosis and parts already confirmed, before the truck rolls.
Industrial equipment runs 10-30 years, generating telemetry in proprietary formats across PLCs, SCADA, and legacy historians. Pre-built AI tools expect clean JSON or CSV, leaving you to write custom parsers for every machine type.
Closed AI platforms force you to accept their pre-trained models. When predictions fail on niche equipment, you cannot retrain on your tribal knowledge corpus or tune for your failure patterns.
Field service management platforms offer bundled AI but trap you in their ecosystem. Switching vendors means rebuilding integrations from scratch, and your historical training data stays locked in their database.
Bruviti provides a headless AI platform designed for developers who need to integrate field service intelligence without replatforming existing FSM systems. The Python and TypeScript SDKs expose core capabilities through REST APIs: parts prediction, failure pattern matching, and knowledge retrieval. You own the data pipeline, control model retraining, and deploy wherever your infrastructure lives.
The platform ingests telemetry from PLCs, SCADA, and IoT sensors using configurable connectors for OPC-UA, Modbus, and MQTT. Developers define custom feature extraction logic in Python, map sensor data to equipment models, and train technician assist models on their own failure histories. Models return predictions with confidence scores and explainability metadata, so technicians understand why the AI recommends specific parts or diagnostic steps.

API-driven parts prediction for CNC machines and turbines. Ingest vibration and temperature data, return ranked parts list with confidence scores before technician dispatch.

Match failure symptoms to tribal knowledge corpus. Developers train models on decades of technician notes to surface root cause patterns for legacy industrial equipment.
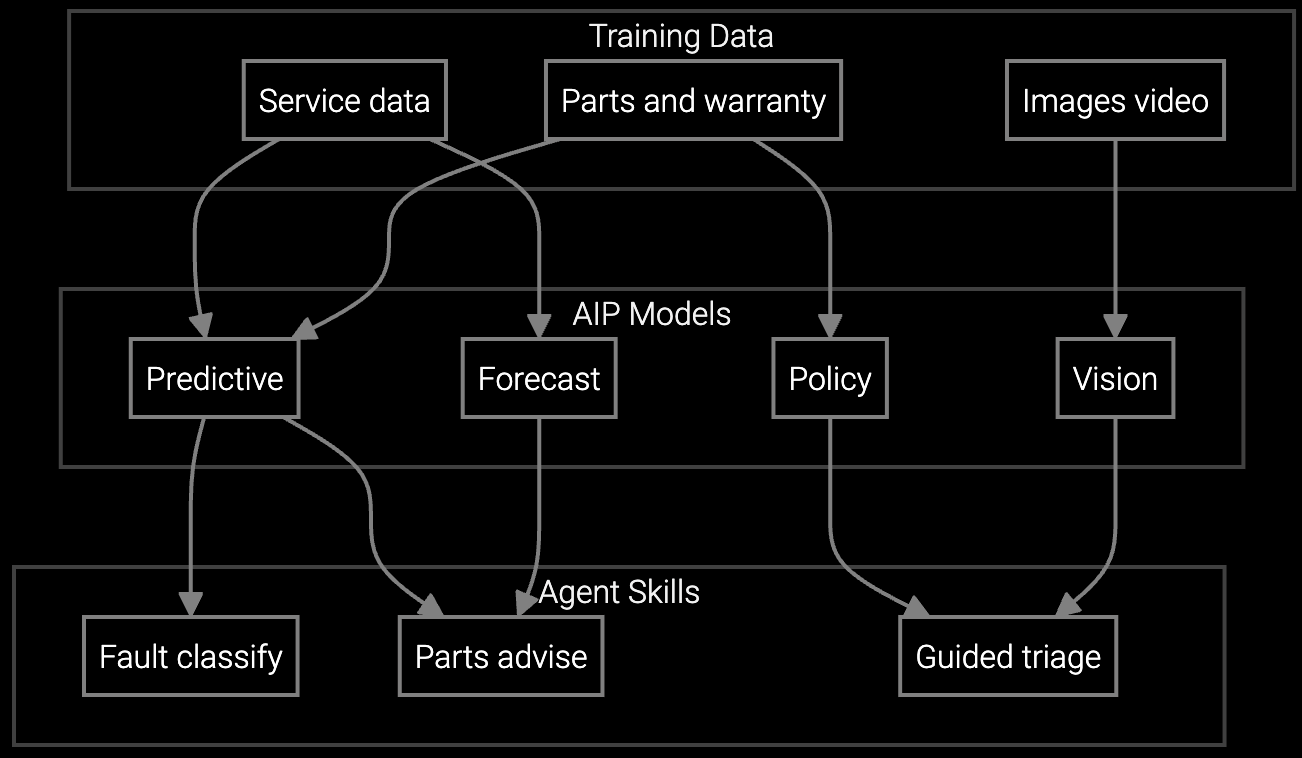
Mobile SDK delivers real-time diagnostic recommendations on-site. Integrates with existing mobile FSM apps to provide step-by-step repair procedures for heavy machinery.
Industrial machinery generates telemetry across decades-old PLCs, modern SCADA systems, and retrofitted IoT sensors. Bruviti's connector framework supports OPC-UA for newer equipment, Modbus RTU/TCP for legacy controllers, and MQTT for edge devices. Developers write custom feature extractors in Python to normalize sensor readings from heterogeneous sources into a unified schema for model training.
For equipment with sparse telemetry, the platform augments sensor data with work order histories, technician debrief notes, and parts consumption logs. This multi-source fusion captures context that pure condition monitoring misses, enabling models to predict failures that only manifest through usage patterns rather than sensor anomalies.
The platform provides native SDKs for Python and TypeScript. Python is recommended for data engineering and model training workflows, while TypeScript serves front-end integrations with mobile FSM apps. Both SDKs expose the same REST API endpoints for parts prediction, failure pattern matching, and knowledge retrieval.
Yes. Bruviti's architecture separates model hosting from training pipelines, allowing developers to define custom training loops using their equipment-specific datasets. You control feature engineering, hyperparameter tuning, and retraining schedules. Models remain in your infrastructure, avoiding vendor lock-in on proprietary training data.
Pre-built connectors support OPC-UA, Modbus TCP/RTU, and MQTT protocols common in industrial environments. Developers configure connection strings, map sensor tags to equipment models, and define sampling intervals. The connector framework handles protocol translation, buffering, and retry logic, eliminating custom integration code.
The parts prediction endpoint accepts JSON payloads with equipment ID, symptom codes, and optional telemetry arrays. Responses return ranked parts lists with confidence scores, historical failure context, and explainability metadata. API documentation includes OpenAPI specs and Python request examples for common industrial equipment types.
The headless architecture exposes all functionality through standard REST APIs, allowing you to integrate with any FSM system or build custom mobile apps. Training data and models remain in your infrastructure, not Bruviti's. You can export model weights, feature pipelines, and training configurations at any time, ensuring portability across platforms.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
Get API documentation, Python code examples, and sandbox access for industrial field service AI.
Access Developer Resources