Decades-long equipment lifecycles mean your parts forecasting must integrate with legacy systems without creating new technical debt.
Bruviti deployment data shows AI-driven parts inventory hits 85% auto-extraction accuracy and answers any parts search query in under 30 seconds. For industrial equipment OEMs, that means catalog and SKU data builds itself from manuals and drawings, so technicians find the right part instantly instead of digging through PDFs.
Connecting AI forecasting to decades-old ERP systems requires custom data pipelines for each equipment generation. Engineering teams waste months building one-off connectors instead of delivering value.
Black-box forecasting platforms trap inventory data and prediction logic in proprietary systems. When the model fails for low-volume parts or seasonal demand, you cannot retrain or customize the algorithm.
Training foundation models from scratch demands scarce ML engineering talent and compute resources. Parts prediction accuracy degrades as equipment ages unless models continuously retrain on new failure patterns.
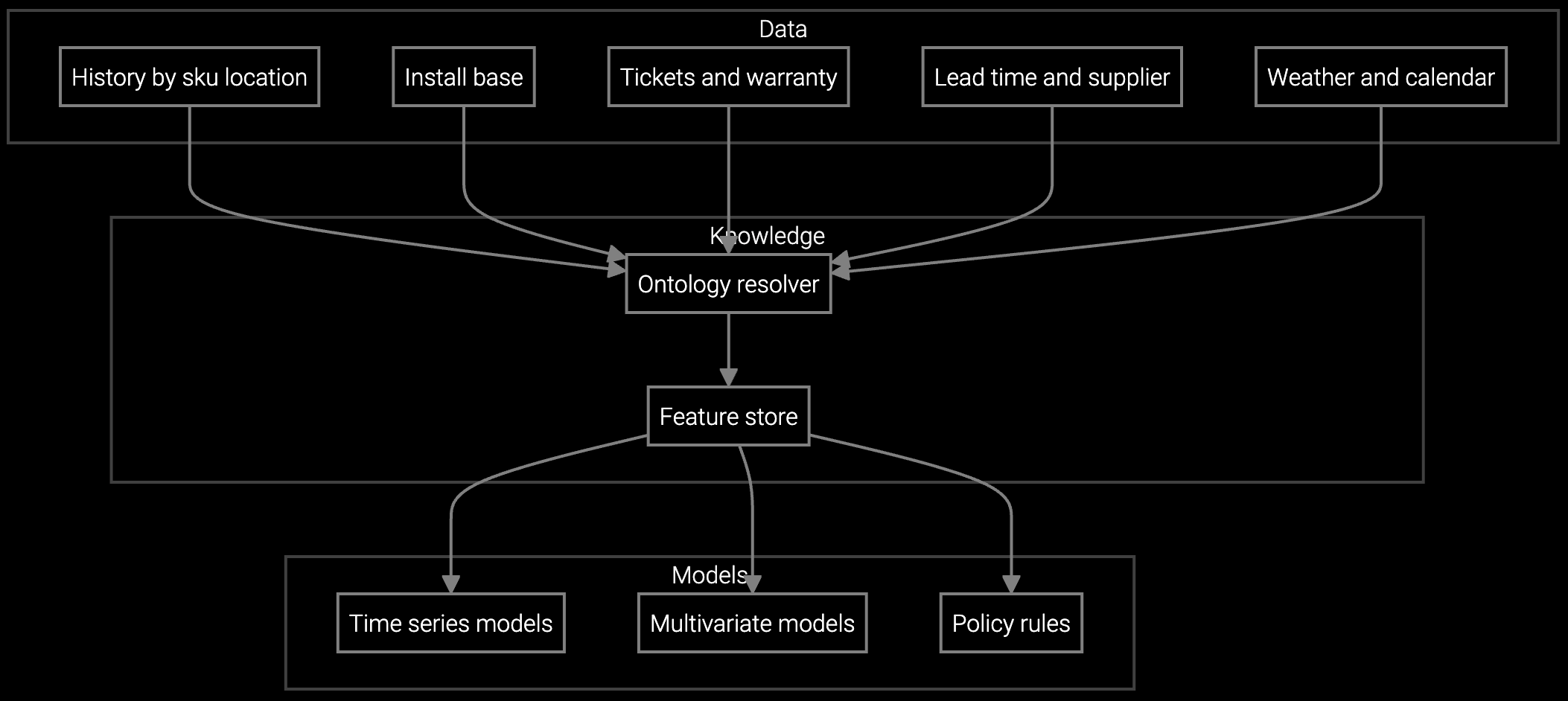
Bruviti provides Python and TypeScript SDKs that expose parts demand forecasting as standard REST APIs. Your engineering team writes integration code once using familiar languages, then deploys prediction endpoints that connect to existing SAP MM, Oracle E-Business Suite, or custom inventory systems. The platform ingests sensor telemetry from PLCs and SCADA systems alongside service history from legacy databases, training forecasting models without requiring you to migrate data warehouses.
The headless design lets you customize prediction logic for specific equipment families while the platform manages model training infrastructure, feature engineering pipelines, and retraining schedules. When forecast accuracy drops for low-volume parts or seasonal demand shifts, your team adjusts hyperparameters or feature sets through version-controlled configuration files. Data stays in your cloud environment with role-based access controls you define, not locked in a vendor's proprietary storage layer.
Train prediction models on decades of installed base telemetry and service records for CNC machines, pumps, and turbines to forecast consumption by equipment age and run hours.

Use REST APIs to pull location-specific demand forecasts into your warehouse management system, optimizing stock levels across global service networks for heavy machinery.

Integrate image recognition APIs that identify worn components from field photos, returning part numbers and availability to speed quoting for industrial equipment repairs.
Industrial OEMs support equipment spanning decades, meaning your forecasting system must ingest telemetry from modern IoT sensors on new CNC machines alongside CSV exports from legacy SCADA systems on 20-year-old turbines. The platform's data connectors normalize PLC tags, vibration sensor streams, and historian databases into a unified feature set for model training. When equipment generations use different part numbering schemes, the SDK's mapping layer translates historical service records into consistent training data without requiring master data migration projects.
For high-value capital equipment like power generation systems or industrial robots, forecast models train on equipment-specific usage patterns—run hours, load cycles, environmental conditions—rather than generic failure curves. Python notebooks let your data engineers experiment with custom features like seasonal maintenance windows or geographic deployment patterns, then promote validated models to production through the platform's CI/CD pipeline. As equipment ages and new failure modes emerge, automated retraining keeps forecast accuracy stable across the entire installed base lifecycle.
The platform provides native SDKs for Python 3.8+ and TypeScript/JavaScript (Node.js 16+). Python SDK includes integration modules for pandas DataFrames and scikit-learn pipelines. REST APIs follow OpenAPI 3.0 specification so you can generate clients for other languages.
Pre-built connectors use standard interfaces (SAP RFC, Oracle E-Business Suite APIs) to extract parts master data, service order history, and inventory transactions. The SDK handles authentication, rate limiting, and delta synchronization. Your team configures field mappings through YAML files without writing custom ETL code.
Yes. The platform provides base forecasting models trained on industrial equipment data, which you fine-tune using your service history and sensor telemetry. Python SDK exposes hyperparameter configuration, feature engineering pipelines, and model evaluation metrics. You control which data sources train which models and can A/B test custom variants.
Data stays in your cloud environment (AWS, Azure, GCP) with encryption at rest and in transit. The platform deploys as containerized services in your VPC, not SaaS multi-tenant storage. You define IAM roles and access policies. Model training jobs run on your compute resources using your data lake or warehouse as the source.
All trained models export to standard ONNX or TensorFlow SavedModel formats. Feature engineering pipelines are version-controlled Python code you own. Historical training data and model artifacts remain in your storage. You can deploy exported models to any inference runtime without platform dependencies or licensing restrictions.

SPM systems optimize supply response but miss demand signals outside their inputs. An AI operating layer makes the full picture visible and actionable.

Advanced techniques for accurate parts forecasting.

AI-driven spare parts optimization for field service.
Talk to our integration architects about API access, sandbox environments, and technical documentation.
Schedule Technical Review