Five-nines uptime demands and firmware complexity force network OEMs to decide: custom-build remote diagnostics or adopt AI platforms now.
Buying a proven network remote support platform cuts L3 escalations by 35% or more, per Bruviti deployment data, without a multi-year build. Senior-engineer capacity is the scarce asset, so the build-vs-buy call hinges on time-to-impact. A pre-trained layer protecting expert time today usually outweighs a custom system that delivers the same escalation reduction far later.
Custom AI development requires 18-24 months for log parsing models, telemetry correlation engines, and guided troubleshooting workflows. Network incidents don't wait—every quarter of delay costs margin and competitive position.
Building remote support AI demands ML engineers familiar with SNMP traps, syslog parsing, and network protocols. Recruiting, training, and retaining this specialized talent drains budget before delivering first remote resolution.
Platform adoption risks vendor lock-in and integration friction with existing NOC tools, ticketing systems, and remote access infrastructure. Every closed API or proprietary data format threatens future flexibility.
Pure build strategies deliver control but miss critical market windows. Pure buy approaches accelerate deployment but risk lock-in to platforms that can't adapt to proprietary telemetry formats or integrate with legacy NOC infrastructure. Network equipment OEMs need a third path.
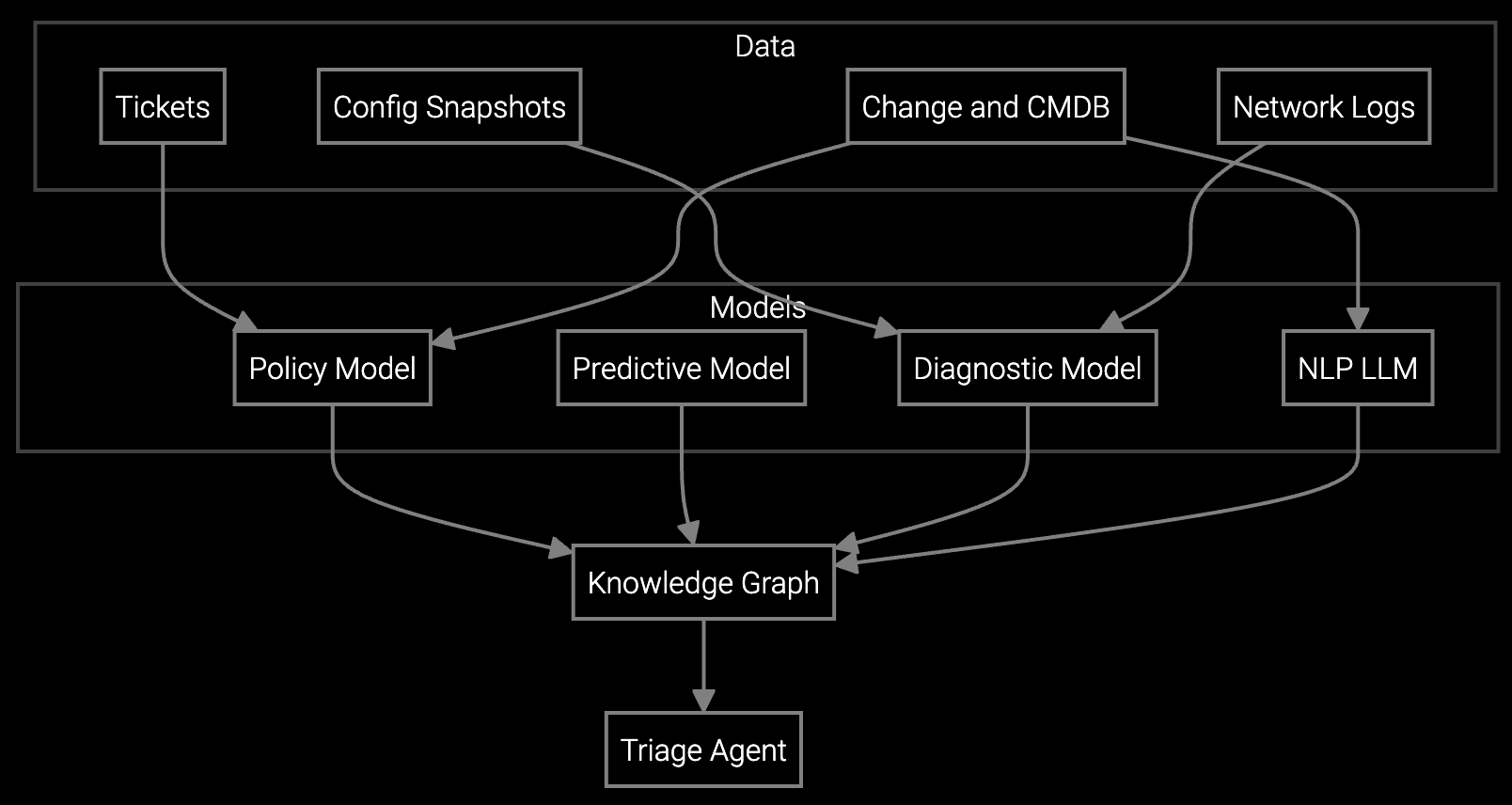
The platform combines pre-built models for log analysis and pattern recognition with API-first architecture for custom integration. Support engineers get AI-executed root cause analysis from SNMP traps and syslog data within weeks, not years. Your team extends the platform using SDKs to parse firmware-specific error codes, integrate with existing remote access tools, and capture institutional knowledge without rebuilding core ML infrastructure. This preserves strategic flexibility while eliminating the expertise acquisition timeline and the $2M+ annual cost of maintaining an in-house AI team.
Network equipment manufacturers serve customers where downtime directly impacts revenue—data centers, carrier networks, enterprise campuses. Every minute of unplanned outage triggers SLA penalties and threatens contract renewals. Remote support teams face unique challenges: routers and switches deployed in hard-to-reach locations generate massive telemetry volumes, firmware updates introduce configuration drift, and security vulnerabilities demand rapid patching across thousands of devices.
Traditional remote support strategies rely on manual log analysis and knowledge silos among senior support engineers. When a customer reports degraded throughput or intermittent packet loss, engineers spend hours parsing syslog output and correlating SNMP trap sequences to identify root cause. This manual approach increases escalation rates and extends MTTR beyond target thresholds—directly impacting your reputation and margin.
Network equipment OEMs typically achieve measurable ROI within 6-9 months by focusing initial deployment on high-volume incident categories like firmware errors or configuration drift. Track remote resolution rate improvements and escalation reduction monthly to quantify margin impact. Early wins in reducing MTTR for critical incidents build executive confidence and fund broader rollout across additional device families and incident types.
Prioritize integrations with syslog aggregation, SNMP trap management, and existing ticketing systems first. These connections enable AI models to ingest real-time telemetry and automatically enrich support tickets with root cause analysis. Secondary integrations with remote access tools and firmware management platforms extend value by enabling support engineers to execute guided troubleshooting and configuration updates without switching contexts across multiple tools.
Evaluate platforms based on API-first architecture and data portability. Ensure the platform exposes SDKs for custom telemetry parsing, supports standard protocols for log ingestion, and provides export capabilities for all training data and model configurations. Test integration flexibility early by connecting proprietary firmware telemetry formats—this reveals whether the platform truly enables customization or forces you into their predefined workflows. Avoid platforms with closed data models or proprietary query languages.
Firmware vulnerability assessment requires specialized models trained on CVE databases, vendor security bulletins, and device configuration data. Building these models in-house demands ongoing maintenance as new vulnerabilities emerge—a continuous expense that diverts ML talent from differentiated capabilities. Platforms with pre-trained security models and automated update mechanisms deliver faster time-to-protection while your team focuses on customizing models for proprietary device features or customer-specific network topologies.
Successful implementation requires network protocol expertise, API integration skills, and basic ML operations knowledge—not deep ML research capabilities. Your existing support engineers bring domain knowledge about device failure patterns and customer environments. Add one or two integration specialists familiar with REST APIs and data pipeline tools to connect telemetry sources. The platform handles model training and inference, eliminating the need to recruit expensive ML researchers or build custom training infrastructure.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
See how Bruviti's hybrid approach delivers speed and flexibility for network equipment OEMs.
Schedule Strategy Discussion