Warranty costs erode margins while legacy systems trap you between slow internal builds and inflexible vendor platforms.
Appliance OEMs face a choice: build custom warranty AI with full control but long timelines, buy vendor solutions risking lock-in, or adopt API-first platforms that combine speed with flexibility. Success requires Python SDKs, open integration, and fraud detection models you can retrain as claim patterns evolve.
Building warranty AI from scratch requires training foundation models, assembling claims datasets, and developing fraud detection algorithms. Meanwhile, competitors deploy faster solutions and capture margin improvements.
Closed warranty platforms force proprietary APIs, make model retraining impossible, and create migration barriers. Your claims processing logic becomes trapped in someone else's black box.
Fraudulent claim tactics shift as connected appliances generate new data streams. Static vendor models cannot adapt, and internal builds struggle to keep pace with retraining demands.
Bruviti's platform delivers pre-trained warranty models through Python and TypeScript SDKs, eliminating foundation model training while preserving full customization rights. You integrate claims processing APIs into SAP, Oracle, or custom data lakes without replacing existing systems. Fraud detection models connect to your entitlement databases and IoT telemetry streams through open connectors, not proprietary middleware.
The headless architecture separates model inference from business logic. Your team writes custom validation rules in Python, tunes NFF thresholds based on product lines, and retrains fraud classifiers when claim patterns shift. Model weights export to your infrastructure, and API keys work across environments. You control the code, own the data, and switch providers if strategy changes.
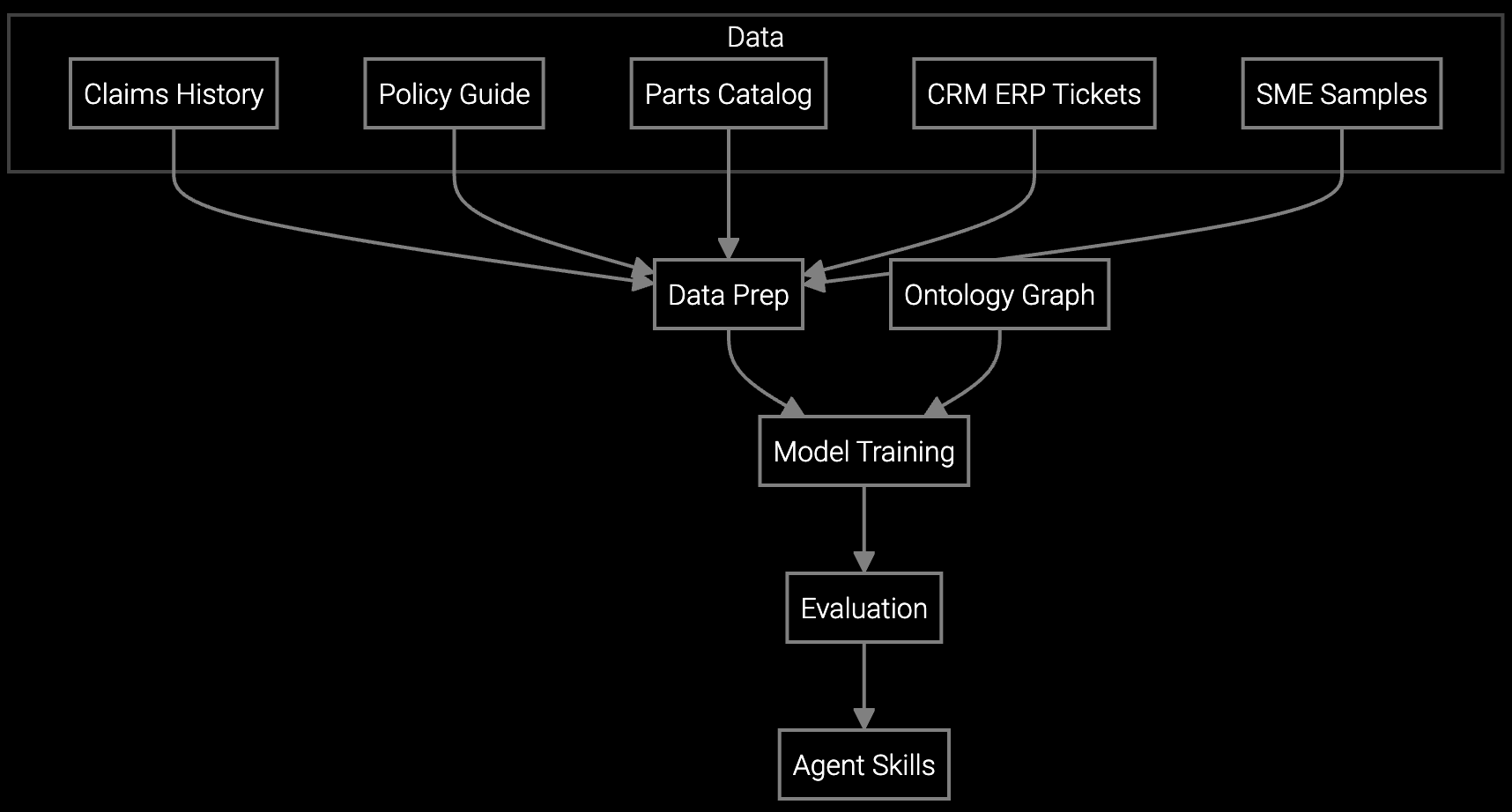
Automate classification and coding for refrigerator, HVAC, and small appliance warranty claims using custom rule engines that integrate with your ERP via REST APIs.

Train custom image classifiers on compressor failures, control board defects, and component degradation patterns using Python-based model retraining workflows.
Appliance manufacturers process thousands of warranty claims weekly across refrigerators, washers, HVAC systems, and small appliances. Building fraud detection from scratch requires training datasets spanning decades of product lines, seasonal failure patterns, and regional claim variations. Vendor platforms offer speed but lock you into proprietary claim routing workflows.
The hybrid approach starts with pre-trained entitlement verification models deployed via API, then adds custom fraud classifiers trained on your claims history. Python SDKs let your team build product-specific NFF reducers for compressor failures, control board defects, and IoT connectivity issues. Models retrain weekly as connected appliance telemetry reveals new failure modes.
Bruviti provides Python SDKs that expose model retraining pipelines. Your data engineers upload new claims datasets, tune hyperparameters, and export updated model weights to production. The platform handles distributed training infrastructure while you control validation logic and threshold tuning.
Yes. The API-first architecture uses REST endpoints that connect to SAP ERP, Oracle Service Cloud, and custom databases. You pass claim payloads to inference APIs and receive fraud scores, entitlement validations, or NFF predictions. Existing RMA workflows remain unchanged.
All training data, model weights, and custom validation rules belong to you. Models export in standard formats like ONNX or TensorFlow SavedModel. Your claims processing logic runs in Python scripts you control, not proprietary vendor runtimes. Migration requires repointing API endpoints, not rebuilding models.
Initial deployment completes in 4-6 weeks using pre-built SDK integrations. You skip foundation model training, dataset labeling infrastructure, and distributed training setup. Custom fraud classifiers add 2-4 weeks for training on your claims history. Full builds typically require 18-24 months.
Yes. Bruviti supports containerized deployments to your Kubernetes clusters or on-premise servers. Model inference runs locally using your infrastructure. Only optional model retraining jobs connect to Bruviti's training infrastructure, and you can disable cloud training entirely for air-gapped environments.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
Test Bruviti's Python SDKs and warranty APIs in your development environment before committing to deployment.
Request API Access