Hyperscale customers demand 99.99% uptime. Manual log analysis delays resolution and escalates costs at scale.
Start with high-volume BMC/IPMI telemetry analysis to automate root cause identification. Integrate with existing remote access tools through API, pilot on compute node failures where session data is richest, and measure remote resolution rate improvement within 90 days.
Support engineers lack visibility into resolved sessions across the organization. Each engineer reinvents diagnosis for common BMC errors and RAID controller failures instead of accessing institutional knowledge.
Support engineers spend hours parsing IPMI logs and thermal sensor data to identify root cause. Critical time lost when hyperscale customers measure downtime in revenue per minute.
Without AI-driven root cause analysis, support engineers escalate complex cases that could be resolved remotely. Each unnecessary escalation delays customer resolution and increases operational costs.
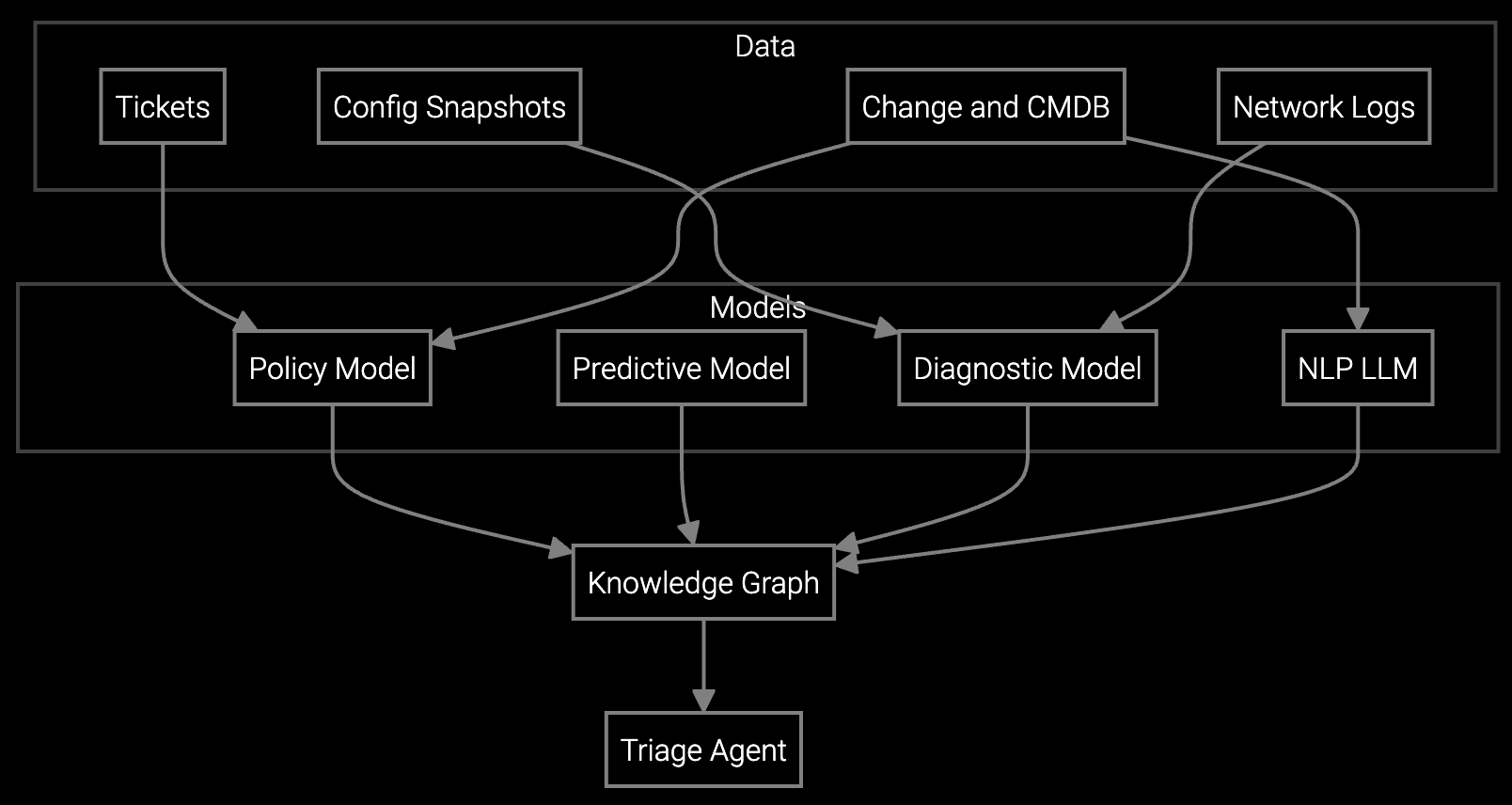
Bruviti integrates with existing remote access infrastructure through API, ingesting BMC/IPMI telemetry, thermal sensor data, and session transcripts to build a real-time knowledge base. The platform learns from every resolved session, automatically tagging root causes and capturing diagnostic patterns that support engineers reuse across future sessions.
Deploy in three phases: first, automate log analysis for compute node failures where telemetry volume is highest. Second, extend guided troubleshooting to storage and cooling systems. Third, implement session-based knowledge capture to surface similar resolved cases during active remote diagnostics. Each phase delivers measurable improvement in remote resolution rate while minimizing change management risk.
Hyperscale customers operate thousands of servers per facility, generating massive telemetry volume from BMC controllers, IPMI interfaces, and thermal sensors. Manual analysis cannot keep pace with failure rates at this scale. Support engineers need instant root cause identification to meet four-nines availability SLAs.
Data center equipment spans diverse hardware generations and vendor configurations. AI platforms trained on historical session data recognize failure patterns across compute nodes, storage arrays, and cooling systems faster than human engineers parsing logs manually. The platform captures diagnostic knowledge from every resolved session, building institutional memory that scales with the organization.
The platform connects via API to existing remote access tools and ingests BMC/IPMI telemetry feeds. Initial setup takes 2-4 weeks including telemetry schema mapping and historical session data import. No replacement of current remote tools required.
Track three metrics: remote resolution rate improvement, escalation rate reduction, and average session duration decrease. Most data center OEMs see measurable improvement within 90 days as the platform learns from resolved sessions and builds its diagnostic knowledge base.
Start with compute node failures where BMC/IPMI telemetry is richest and failure patterns are most consistent. Expand to storage systems and cooling infrastructure after validating ROI on initial deployment. Prioritize equipment with highest support incident volume.
The platform learns failure patterns across different server generations, storage vendors, and cooling system types through historical session analysis. Configuration-specific diagnostics improve as the system ingests more telemetry from each hardware variant in your installed base.
Minimal training required since the platform integrates with existing remote access workflows. Engineers receive automated root cause suggestions during active sessions and can access similar resolved cases through the interface. Most teams reach full adoption within 30 days.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
See how Bruviti deploys AI for data center remote support operations.
Schedule Implementation Review