Distributed warehouses create data silos that turn simple stock checks into integration nightmares for teams building service systems.
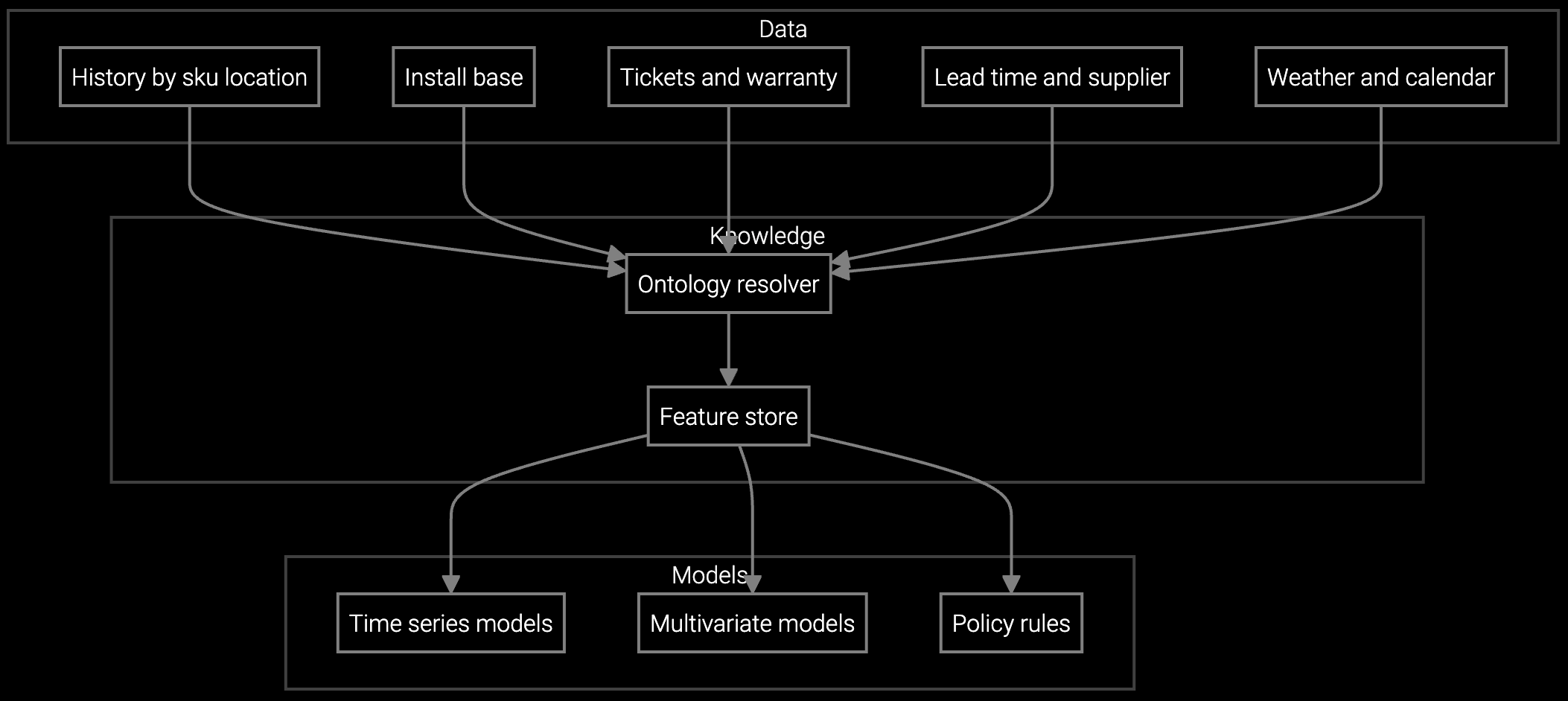
Integrate real-time inventory data across geographically distributed warehouses using APIs that normalize location codes, sync stock levels, and flag discrepancies between ERP systems and physical counts at edge locations.
Legacy ERP systems assign inconsistent warehouse identifiers across regions. One location might be "US-WEST-01" in SAP and "PDX-DC-A" in Oracle, breaking automated queries and forcing manual lookups.
Parts picked from warehouse A don't update in the central system for 15-60 minutes. Developers building real-time allocation logic hit stale data that shows availability for parts already consumed in another region.
Edge facilities handling thousands of SKUs accumulate discrepancies from mis-picks, incorrect cycle counts, and unlogged emergency pulls. No automated reconciliation means your app shows parts that don't exist.
Build a unified inventory view by connecting Bruviti's APIs to each regional system through lightweight Python or TypeScript adapters. The platform maintains a master location registry that maps all naming variants to canonical warehouse IDs, so your code queries one endpoint and receives normalized responses regardless of backend diversity.
Real-time discrepancy detection compares ERP transactions against AI-predicted consumption patterns based on service ticket velocity and historical usage. When physical counts diverge from system records by more than threshold percentages, webhooks alert your orchestration layer to trigger cycle counts or flag suspect data before allocation decisions. Developers retain full control over tolerance settings and escalation logic through configuration files.

Forecast server component demand by data center location and time window, optimizing stock levels for power supplies and memory modules while reducing carrying costs.
Project cooling system parts consumption based on installed CRAC unit age, thermal load patterns, and seasonal trends across hyperscale facilities.

Snap a photo of a failed PDU component or storage drive and get instant part number identification with availability across your regional warehouse network.
Data center infrastructure OEMs support thousands of customer sites spanning continents, each requiring localized parts inventory for SLA compliance. A hyperscale customer in Virginia can't wait for a replacement UPS module to ship from Singapore when PUE targets and uptime commitments demand same-day resolution.
This geographic distribution multiplies integration complexity. Each regional hub runs different inventory management systems based on acquisition history and local IT preferences. Your parts allocation API must query Tokyo's JDE system, Frankfurt's SAP instance, and Atlanta's custom PostgreSQL database, then reconcile results into a single availability response for service dispatch logic to consume.
Use the platform's location registry API to register each warehouse's identifiers once during initial setup. The service maintains bidirectional mappings and returns canonical location IDs in all responses. Your code queries using any known variant and receives normalized data without maintaining mapping logic.
Batch update cycles in legacy systems create delays between physical picks and central inventory updates. Configure the API to flag quantities as "pending verification" when transaction timestamps indicate recent activity. Your allocation logic can then reserve buffer stock or query directly at the warehouse level for critical parts.
Yes, the platform accepts tolerance rules via JSON configuration where you define acceptable variance percentages per part class. High-value server components might trigger alerts at 5% discrepancy while consumables like cables allow 15%. Webhook payloads include both the delta and your defined threshold for context.
The system analyzes historical service ticket patterns, installed base age curves, and seasonal trends to forecast expected parts usage per location. When actual ERP-reported consumption significantly undershoots predictions while stock levels remain static, it flags potential counting errors or unlogged pulls for investigation.
Supply a CSV or API endpoint listing each warehouse's identifier variants, physical address, and parent ERP system. The platform ingests this during onboarding and maintains synchronization. As you add locations or rename facilities, POST updates to the registry endpoint to keep mappings current without code changes.

SPM systems optimize supply response but miss demand signals outside their inputs. An AI operating layer makes the full picture visible and actionable.

Advanced techniques for accurate parts forecasting.

AI-driven spare parts optimization for field service.
Get API documentation and sandbox access to test multi-location reconciliation with your warehouse systems.
Request Developer Access