Data center agents search 6+ systems for server configs, BMC logs, and RAID status—every minute wasted costs uptime.
Knowledge fragmentation forces agents to search multiple systems for BMC logs, RAID configs, and power telemetry. A unified API layer ingests equipment data into a single knowledge graph, enabling sub-second retrieval and reducing handle time by 40%.
Agents toggle between ticketing, IPMI interfaces, asset databases, knowledge bases, and vendor portals. Each lookup adds latency and context-switching overhead that compounds across thousands of daily cases.
BMC logs, SNMP traps, and syslog formats differ across vendors and hardware generations. Agents manually correlate thermal alerts, power events, and RAID failures without standardized schemas.
Case history lives in CRM, equipment data in CMDB, thermal patterns in monitoring tools. No API aggregates these sources, so agents reconstruct server state from fragments during every interaction.
The fragmentation problem stems from architectural isolation. Each data source—asset DBs, monitoring systems, ticketing platforms—exposes different schemas and access patterns. Building a custom integration layer means maintaining hundreds of API connectors, transform pipelines, and version-specific parsers.
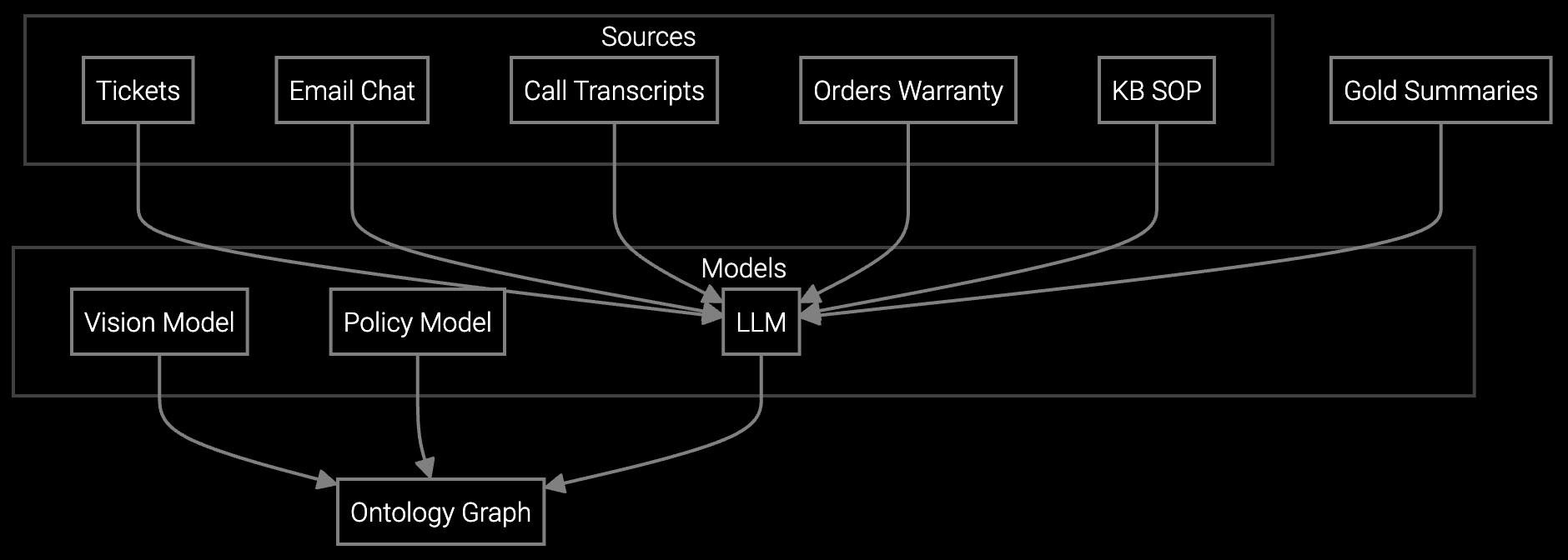
Bruviti provides a headless knowledge graph that ingests telemetry streams via REST APIs and webhook subscriptions. Python SDKs normalize BMC data, SNMP traps, and syslog events into a unified entity model. Agents query a single endpoint that surfaces equipment state, failure history, and resolution paths without custom code for each vendor integration.
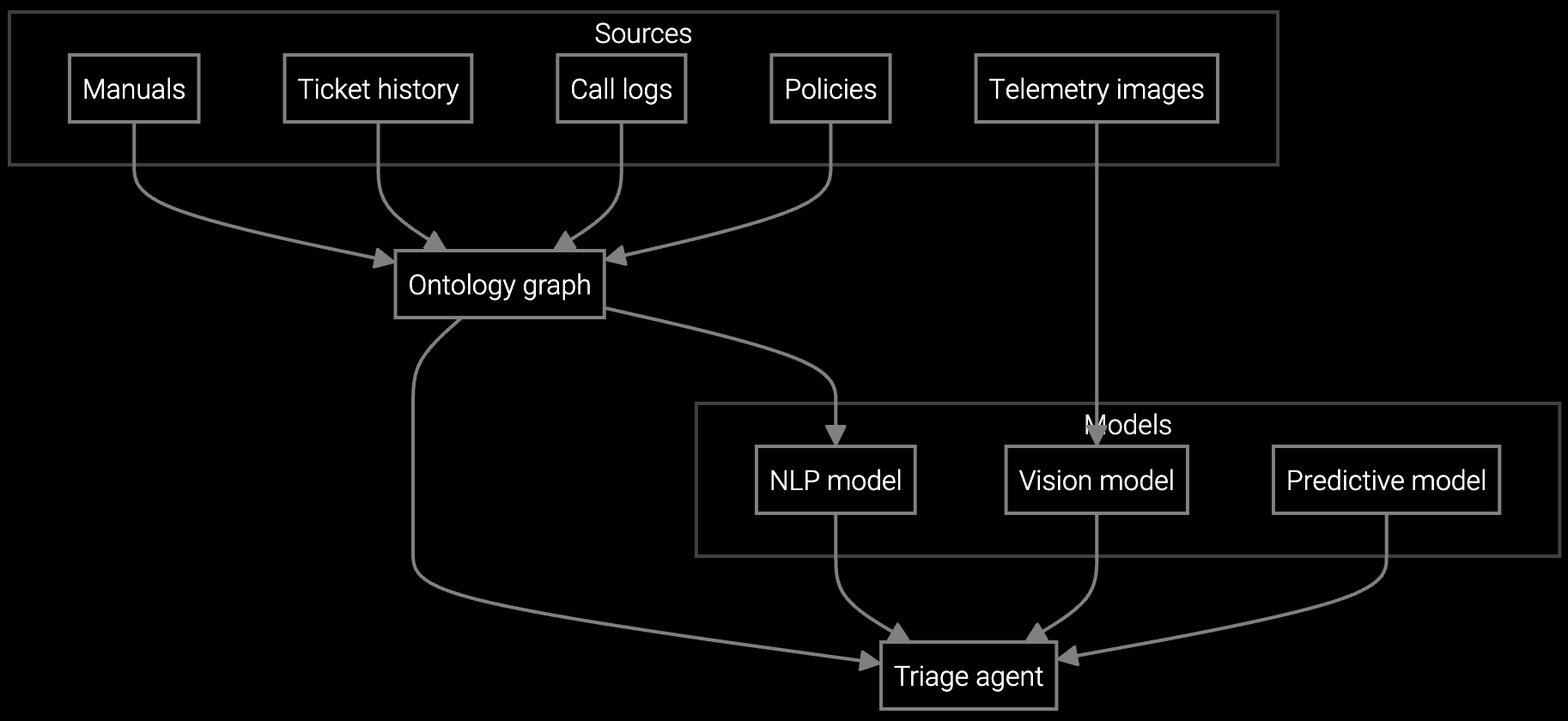
Autonomous case classification analyzes BMC alerts, correlates power and thermal telemetry, and routes to compute, storage, or cooling teams with diagnostic context attached.
Instantly generates case summaries from emails, IPMI logs, and chat transcripts so agents understand server history without reading 50+ log entries per case.

AI reads customer emails describing RAID failures or thermal alerts, classifies severity from attached BMC logs, and drafts responses using historical resolution data.
Hyperscale operators manage millions of servers across distributed racks, each generating thousands of telemetry events daily. Enterprise data centers juggle multi-vendor hardware—Dell, HP, Supermicro, custom white-box builds—with different BMC implementations and logging formats.
Agents handle cases spanning compute nodes, storage arrays, PDUs, and cooling systems. A single thermal alert might cascade from CRAC failure, but without unified context, agents chase symptoms across isolated monitoring dashboards until root cause emerges hours later.
Bruviti's Python SDK parses vendor-specific formats (IPMI SEL, Redfish events, proprietary XML) into a common schema with standardized severity levels and event types. You can extend parsers for custom hardware without modifying core ingestion logic.
Yes. The REST API returns JSON responses that embed in CRM sidebars or chat interfaces. Agents see server history, related cases, and resolution suggestions inline without opening separate tabs.
The platform flags missing telemetry streams and shows last-updated timestamps per data source. Agents see confidence scores on recommendations so they know when to escalate rather than guess from partial information.
All integrations use standard REST endpoints and OpenAPI specs. Your Python or TypeScript code calls generic functions—switch backends by updating config files, not rewriting application logic. Export your knowledge graph data anytime.
Proof-of-concept with one equipment type takes 2-4 weeks. Adding vendor-specific telemetry parsers averages 1 week per hardware family. Full production rollout across compute, storage, and power systems typically completes in 8-12 weeks.

Transforming appliance support with AI-powered resolution.

Understanding and optimizing the issue resolution curve.

Vision AI solutions for EV charging support.
See how Bruviti's API layer unifies data center telemetry without vendor lock-in.
Talk to an Engineer