When agents toggle between six systems to answer one router question, your MTTR target becomes impossible.
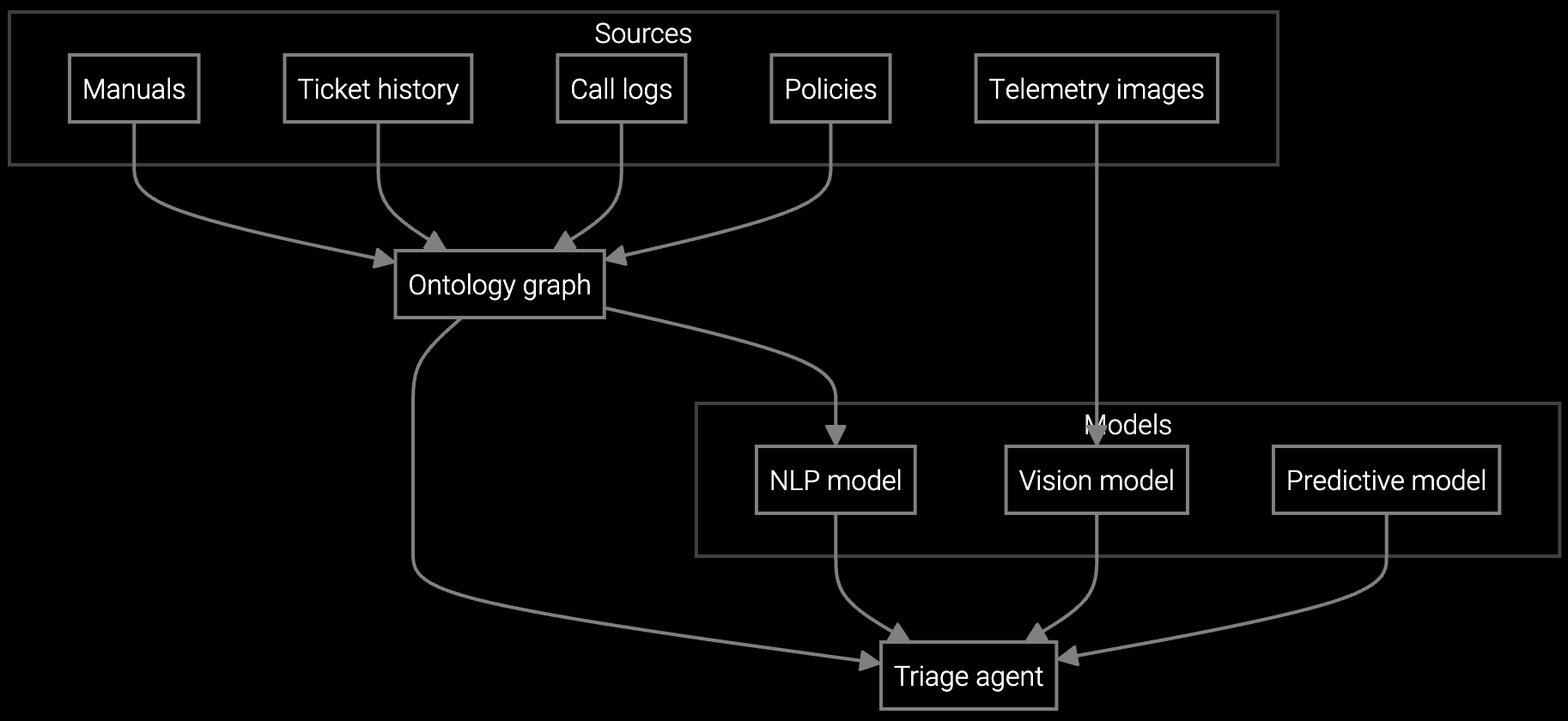
Network equipment OEMs face fragmented knowledge across legacy ticketing systems, outdated wikis, and tribal know-how. AI-powered knowledge retrieval unifies documentation, syslog patterns, and case history into a single API-accessible layer that agents query in real time, reducing resolution time without replacing existing tools.
Agents waste cycles switching between ServiceNow, Confluence, internal wikis, and email threads to locate firmware bulletins, known CVE workarounds, and RMA procedures. Each context switch adds latency and cognitive load.
Network equipment evolves faster than internal documentation. Agents encounter outdated troubleshooting steps for legacy firmware versions while current escalation paths remain undocumented, forcing tribal knowledge reliance.
Resolved cases containing diagnostic gold—like syslog patterns preceding PSU failures—sit locked in closed tickets. Agents cannot surface similar cases without manual keyword archaeology across thousands of records.
The platform ingests structured and unstructured data from existing systems—ticketing APIs, Confluence exports, Jira comments, email threads—and indexes them in a unified semantic layer. When an agent queries "BGP flapping on ASR9K after IOS-XR 7.3.2 upgrade," the system retrieves relevant firmware bulletins, similar closed cases, and SNMP trap patterns without requiring the agent to specify which system to search.
Builders integrate via RESTful API or Python SDK. The knowledge retrieval endpoint accepts natural language queries and returns ranked results with source attribution (ticket ID, doc version, timestamp). No data leaves your environment—deploy on-premises or in your VPC. The architecture avoids vendor lock-in: you retain full ownership of indexed knowledge and can export embeddings in standard formats.
Autonomous classification analyzes syslog errors and SNMP traps from routers and switches, routing hardware failures to RMA while flagging firmware bugs for engineering escalation.
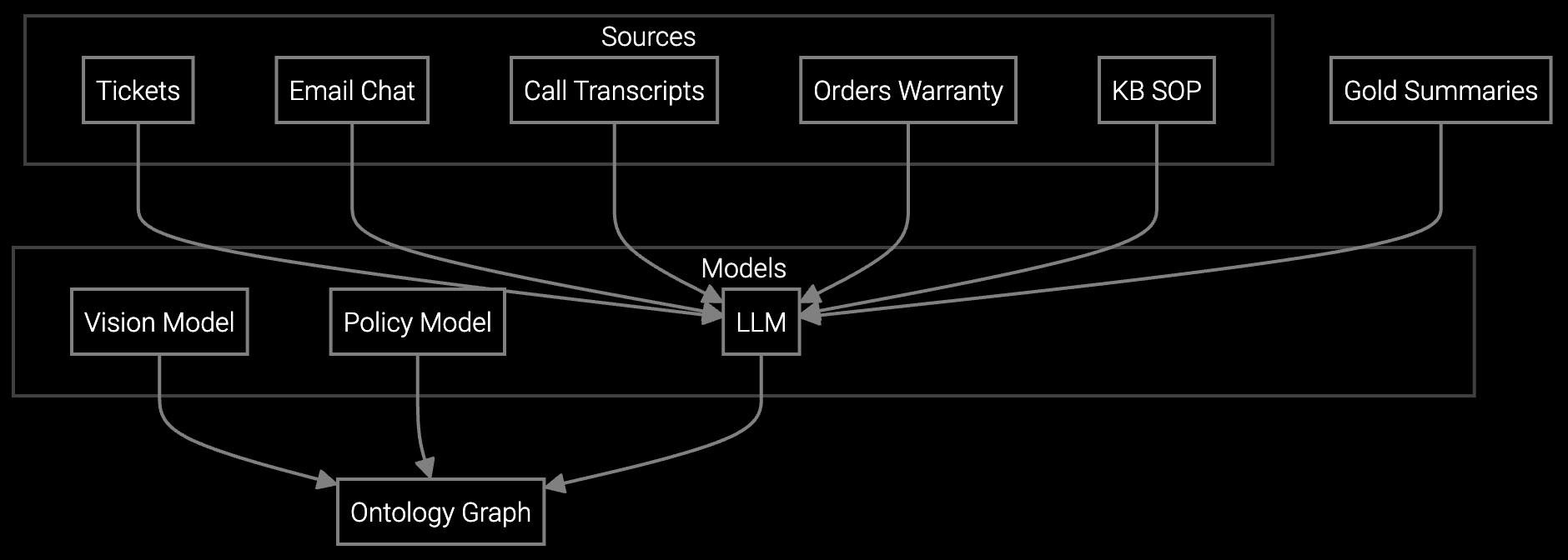
Generates concise summaries from multi-thread email chains and chat logs, surfacing firmware version, error codes, and previous RMA attempts so agents understand network outage context instantly.

AI reads incoming emails describing network issues, extracts device model and symptoms, retrieves relevant troubleshooting steps from knowledge base, and drafts response with firmware patch links.
Network OEMs support thousands of device SKUs across carrier-grade routers, enterprise switches, and security appliances—each with distinct firmware branches, EOL timelines, and failure modes. Agents fielding calls about BGP route leaks, PoE power budget issues, or DWDM laser degradation need instant access to device-specific diagnostics, not generic networking theory.
The platform indexes SNMP MIBs, syslog message catalogs, and firmware release notes alongside closed case outcomes. When an agent sees "Port 0/1/3 SFP TX fault" in a ticket, the system retrieves similar cases showing whether this indicates a failed transceiver (RMA eligible) or a fiber patch issue (customer-actionable).
The indexing layer tags each knowledge artifact with applicable firmware version ranges extracted from release notes and case metadata. When an agent queries about a specific device, the retrieval filters results to match the firmware version reported in the case context, preventing agents from applying obsolete workarounds to current builds.
Yes. The Python SDK exposes ranking parameters that let you assign source-specific weights during index creation. You can boost internal wiki articles by 2x and vendor PDFs by 0.5x, ensuring agent-validated procedures surface above generic manufacturer docs. Retraining runs locally using your labeled preference data.
The API response includes a confidence score and source provenance for each retrieved result. When conflicting answers appear, the system ranks by recency and case outcome data—if 15 recent cases closed successfully using procedure A but only 2 used procedure B, procedure A ranks higher. Agents see the reasoning and can escalate ambiguous cases.
The platform surfaces retrieved knowledge with explicit source citations (ticket ID, document URL, timestamp) rather than generating free-form answers. Agents see "This solution appeared in Case #47291, resolved 2024-12-15" and can click through to verify context. This design prevents hallucination and maintains agent accountability.
Yes. The indexing pipeline ingests case outcome labels (FCR, escalated, RMA issued) and uses them as training signals. Over time, the model learns to prioritize knowledge artifacts that historically led to first contact resolution and downrank procedures frequently preceding escalation. This feedback loop improves as case volume grows.

Transforming appliance support with AI-powered resolution.

Understanding and optimizing the issue resolution curve.

Vision AI solutions for EV charging support.
See how API-first knowledge unification reduces context switching without replacing your CRM.
Talk to an Engineer