Five-nines uptime SLAs and distributed technician expertise make this decision critical right now.
Network OEMs face a build vs. buy decision for field service AI. Building custom models offers control but requires sustained ML expertise. Buying platform solutions delivers faster time-to-value with API flexibility, avoiding both proprietary lock-in and the ongoing burden of maintaining training infrastructure.
Building in-house means maintaining GPU clusters, versioning training pipelines, and retaining ML engineers who understand network telemetry. Most OEMs underestimate the sustained investment required to keep models current as equipment portfolios evolve.
Traditional service platforms trap data in proprietary schemas and offer limited APIs. Developers lose the ability to customize failure prediction logic or integrate telemetry from multi-vendor NOC environments without expensive professional services.
Network technicians carry tribal knowledge about firmware-specific failure patterns and site-specific configuration issues. Neither pure build nor pure buy approaches address how to systematically convert retiring expertise into training data without disrupting daily dispatch operations.
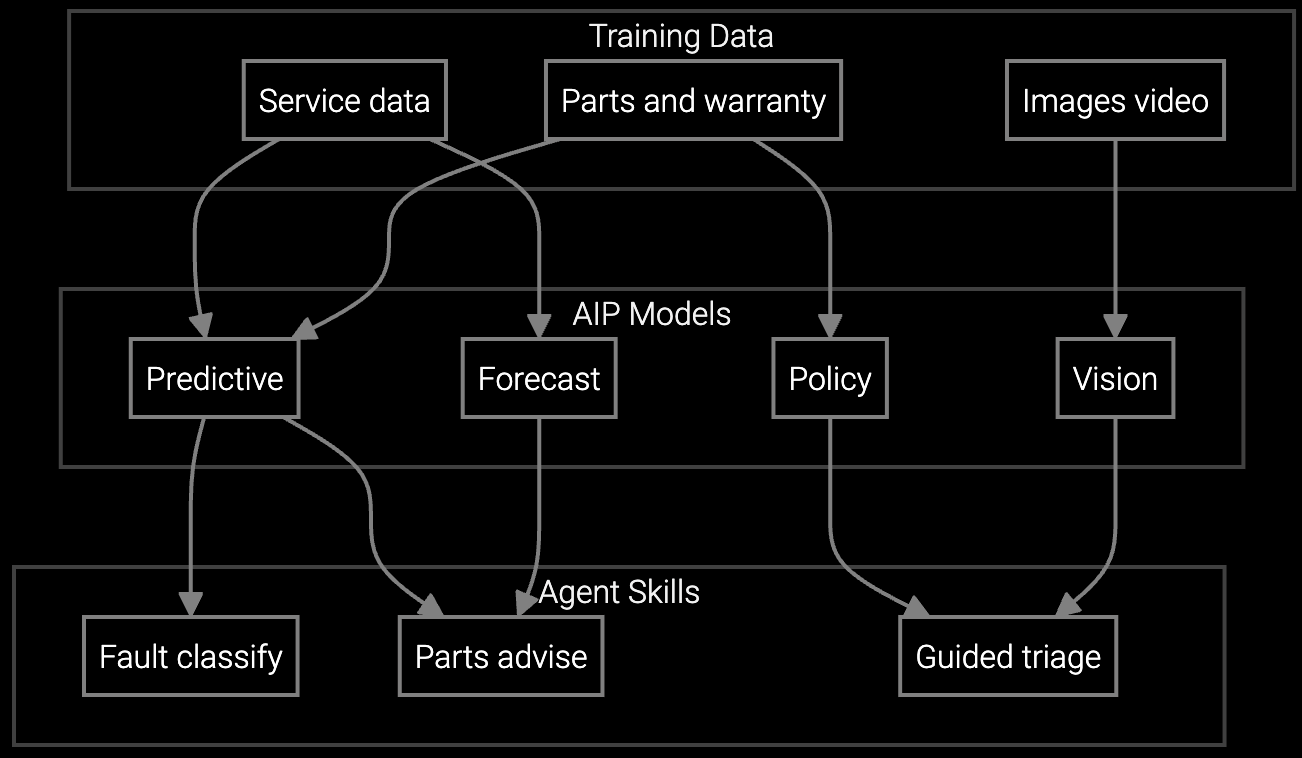
The optimal approach combines pre-trained foundation models with API-first architecture that preserves technical control. Bruviti's platform provides Python SDKs for custom failure prediction logic while handling the infrastructure burden of training on network telemetry patterns across manufacturers. Developers write custom integrations to SNMP traps, syslog parsers, and FSM systems without vendor lock-in.
This hybrid strategy delivers immediate value through pre-built models for common failure modes (power supply degradation, optical transceiver drift) while allowing in-house teams to extend the platform with proprietary logic for firmware-specific issues or multi-vendor topology analysis. The API exposes model confidence scores and intermediate reasoning steps, enabling technical teams to audit and refine AI recommendations before they reach technicians.

Pre-stages optical modules and power supplies based on syslog patterns, reducing repeat truck rolls for router and switch repairs.

Correlates SNMP traps with historical firmware issue databases to identify root cause before dispatching network technicians.
Mobile SDK delivers firmware-specific troubleshooting steps and configuration rollback procedures to technicians on-site at NOC locations.
Network equipment manufacturers operate under five-nines uptime SLAs where a single router failure can cascade into enterprise-wide outages. The distributed nature of installations—from carrier-grade NOCs to remote branch offices—makes technician expertise capture critical. Legacy approaches relied on senior engineers documenting known failure patterns in wikis, but firmware complexity now outpaces manual knowledge transfer.
The build vs. buy decision hinges on whether your engineering team has sustained bandwidth to maintain ML pipelines as your equipment portfolio evolves. Network OEMs releasing quarterly firmware updates face a choice: dedicate scarce ML talent to retraining failure prediction models, or adopt a platform that continuously learns from telemetry across customer deployments while exposing APIs for proprietary logic.
Building requires sustained ML engineering talent with domain expertise in network telemetry, GPU infrastructure for training, and version control for models tied to firmware releases. Most OEMs underestimate the ongoing cost of retraining as equipment portfolios and failure patterns evolve. You also need data engineering pipelines to normalize syslog formats and SNMP schemas across device families.
Bruviti exposes RESTful APIs and Python SDKs that let developers write custom integration logic, query model confidence scores, and export training data in open formats. Unlike proprietary FSM platforms that trap telemetry in closed schemas, API-first architecture means your team retains the ability to switch vendors, extend models, or build custom failure prediction logic without rewriting integrations.
Yes, if the platform provides data export capabilities and API documentation. The key is choosing a vendor that exposes intermediate model outputs and training data access so your team can extract learnings and retrain independently if strategic priorities shift. Avoid platforms that obscure model logic or restrict data portability, as these create irreversible dependencies.
Effective expertise capture requires lightweight mobile interfaces that let technicians annotate repair decisions in real-time rather than post-shift documentation. The platform should auto-generate training examples from work order outcomes, part replacements, and diagnostic steps taken, converting operational data into model improvements without requiring engineers to manually curate knowledge bases.
Network OEMs typically see measurable first-time fix improvements within 90 days on high-volume failure categories like power supply replacements or optical module swaps. Full ROI including reduced truck roll costs and SLA penalty avoidance usually materializes within 12-18 months, compared to 24-36 months for custom-built solutions that require establishing training infrastructure from scratch.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
Talk to Bruviti's technical team about API architecture and integration patterns for your network equipment portfolio.
Schedule Technical Discussion