When thousands of server alerts flood your queue daily, misrouted cases cost hours you don't have.
Bruviti deployment data shows AI triage reduces support call volume 35% and lifts first-call resolution 16%. Operators solve slow triage by letting AI classify and route incoming issues instantly, deflecting routine cases and getting complex ones to the right specialist on the first attempt.
Agents read raw BMC logs and IPMI error codes to determine if the issue is power, thermal, memory, or storage. Every minute spent decoding alerts delays resolution and burns SLA time.
Incorrectly assigned tickets bounce between teams (cooling specialists get compute issues, storage experts get PDU failures). Each handoff adds delay and frustration.
Agents toggle between ticketing system, BMC interface, knowledge base, and parts inventory to gather context. The swivel-chair workflow kills throughput.
Bruviti's platform ingests BMC telemetry, IPMI alerts, and historical case data to automatically classify incidents by root subsystem. When a ticket arrives, the system parses error codes, correlates with recent failures across the fleet, and routes to the specialized team (power, cooling, compute, storage) with a diagnostic summary already attached.
Agents see pre-populated context: affected hardware, similar past cases, and recommended first steps. No manual log reading, no guessing which team should own it. Triage becomes a review task instead of an investigation. The platform learns from routing corrections, improving accuracy over time.
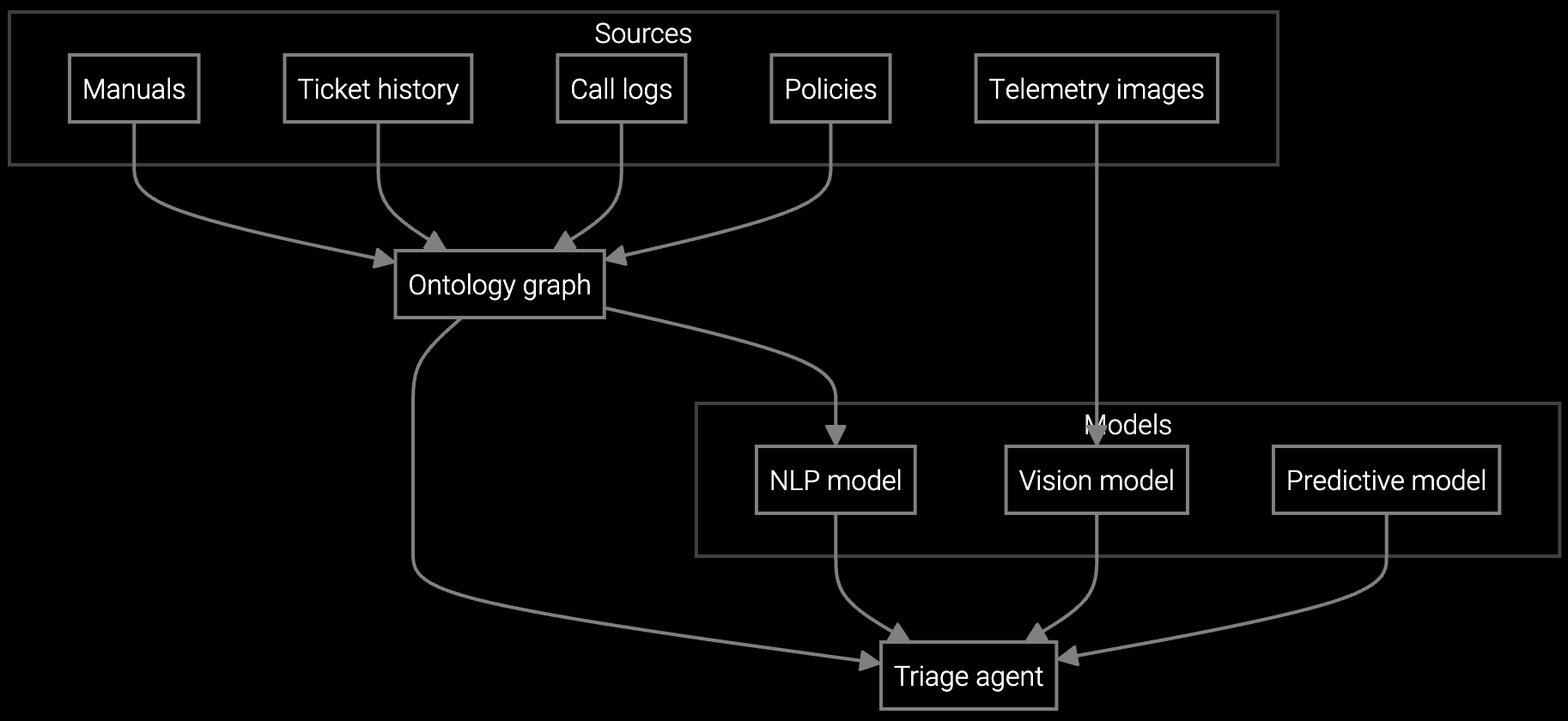
Autonomous case classification analyzes BMC logs and IPMI alerts to route data center incidents by subsystem with diagnostic context.
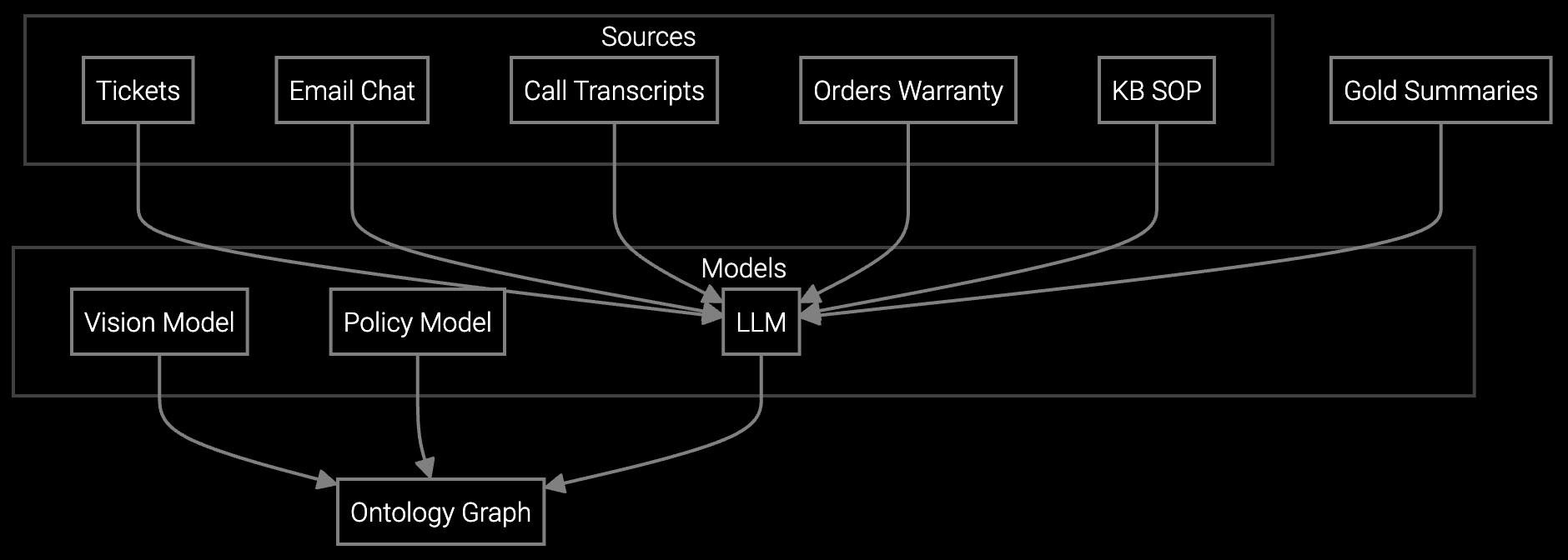
Instantly generates case summaries from alert logs and telemetry streams so agents understand incident history without reading everything.
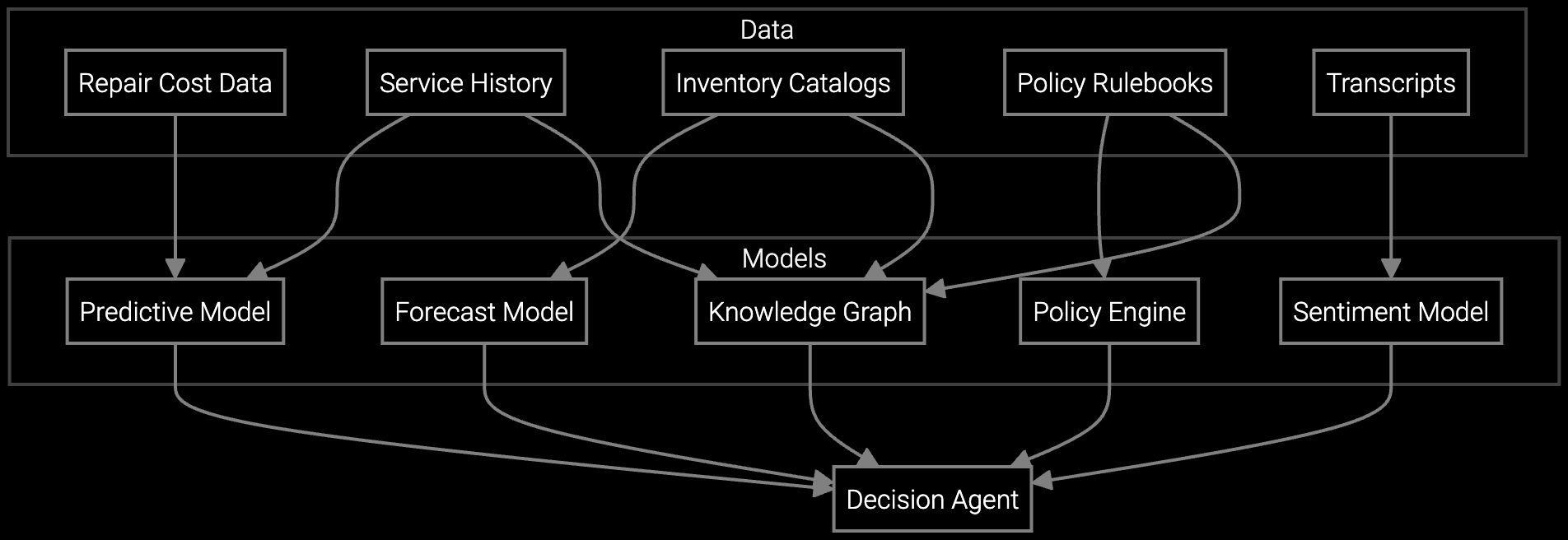
AI analyzes failure modes and server age to recommend RMA versus firmware update for data center hardware issues.
Hyperscale data centers generate thousands of BMC alerts daily across power distribution, thermal management, compute nodes, and storage arrays. Generic ticketing systems treat all incidents the same, forcing agents to manually decode IPMI error codes and guess which specialized team should handle each case.
With four-nines availability targets and tight SLAs, misrouted cases directly impact customer uptime. AI triage correlates hardware telemetry with historical patterns to classify incidents by subsystem before an agent even opens the ticket, ensuring the right expert sees the right problem immediately.
The system parses BMC logs and IPMI alerts to extract error codes, correlates them with historical cases, and matches the failure signature to one of the predefined subsystems (power, cooling, compute, storage). Agents review and correct misclassifications, which trains the model to improve accuracy over time.
Agents reassign the ticket with a single click, and the system logs the correction as feedback. These corrections refine the routing logic, reducing future misrouting rates. Most platforms achieve sub-10% misrouting after 90 days of learning.
Yes. The platform ingests telemetry via API from standard BMC interfaces (IPMI, Redfish) and correlates alerts with your ticketing system. No need to replace existing monitoring infrastructure—just connect the data feeds.
The platform pulls BMC logs, case history, and parts availability into a single view alongside the ticket. Agents no longer toggle between monitoring dashboards, knowledge bases, and inventory systems to gather context—everything appears in the case summary.
The system normalizes telemetry from different BMC implementations (Dell iDRAC, HP iLO, Supermicro IPMI) into a unified format. Multi-vendor environments benefit from consistent classification logic across the entire fleet, regardless of hardware diversity.

Understanding and optimizing the issue resolution curve.

Part 1: The transformation of IT support with AI.

Part 2: Implementing AI in IT support.
See how AI-powered routing gets the right cases to the right team in seconds.
See Platform Demo