Hyperscale operators demand instant resolution—choosing the wrong architecture costs you both speed and control.
Data center OEMs face a choice: build custom service AI in-house or buy closed platforms. A hybrid approach using API-first architecture with pre-trained models offers speed without lock-in, letting teams extend and customize using Python SDKs while avoiding multi-year build cycles.
Building AI for case routing, knowledge retrieval, and BMC telemetry parsing requires assembling training data, hiring ML engineers, and iterating on models. Most internal builds stall at proof-of-concept because production-grade service AI needs continuous retraining as equipment evolves.
Closed service platforms force you into proprietary data formats and limit integration with existing IPMI monitoring, ticketing systems, and custom analytics. When the platform cannot parse new server telemetry or connect to your SAP backend, you are stuck filing support tickets instead of shipping code.
Stitching together best-of-breed tools—one for email triage, another for knowledge search, a third for telemetry analysis—creates brittle integrations. Every API version change or data schema shift requires custom middleware, turning your team into full-time integration maintainers.
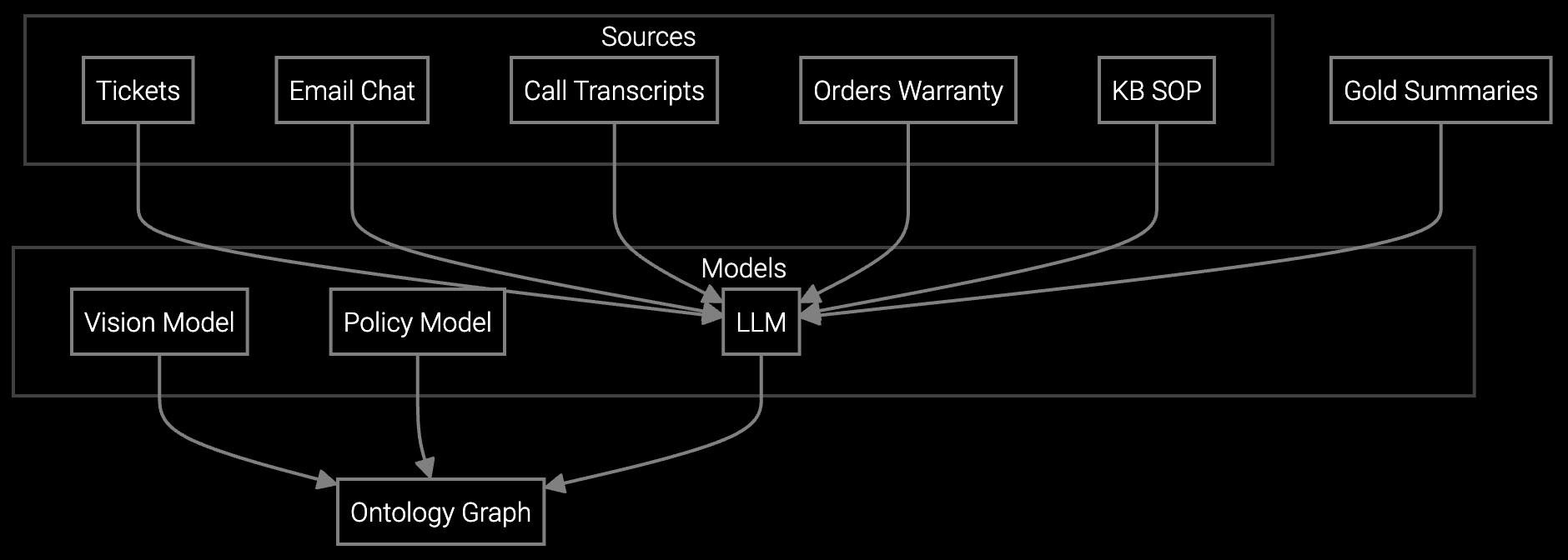
Bruviti provides pre-trained models for case classification, knowledge retrieval, and telemetry analysis while exposing every layer through RESTful APIs and Python SDKs. You deploy the platform in your VPC or on-premises, connect it to your existing Zendesk or ServiceNow instance, and immediately gain AI-assisted triage. Then extend it: write custom parsers for proprietary IPMI logs, retrain classifiers on your case taxonomy, or build agent copilots that surface internal runbooks.
The platform ingests BMC telemetry, syslog streams, and case history without requiring data migration to a vendor's cloud. When hyperscale customers report thermal anomalies, the system correlates IPMI sensor data with historical hot-spot patterns and surfaces relevant troubleshooting steps to agents in real time. Because you own the integration layer, you can route escalations to your custom workflow engine or inject pre-failure alerts into your capacity planning dashboard without waiting for vendor roadmaps.
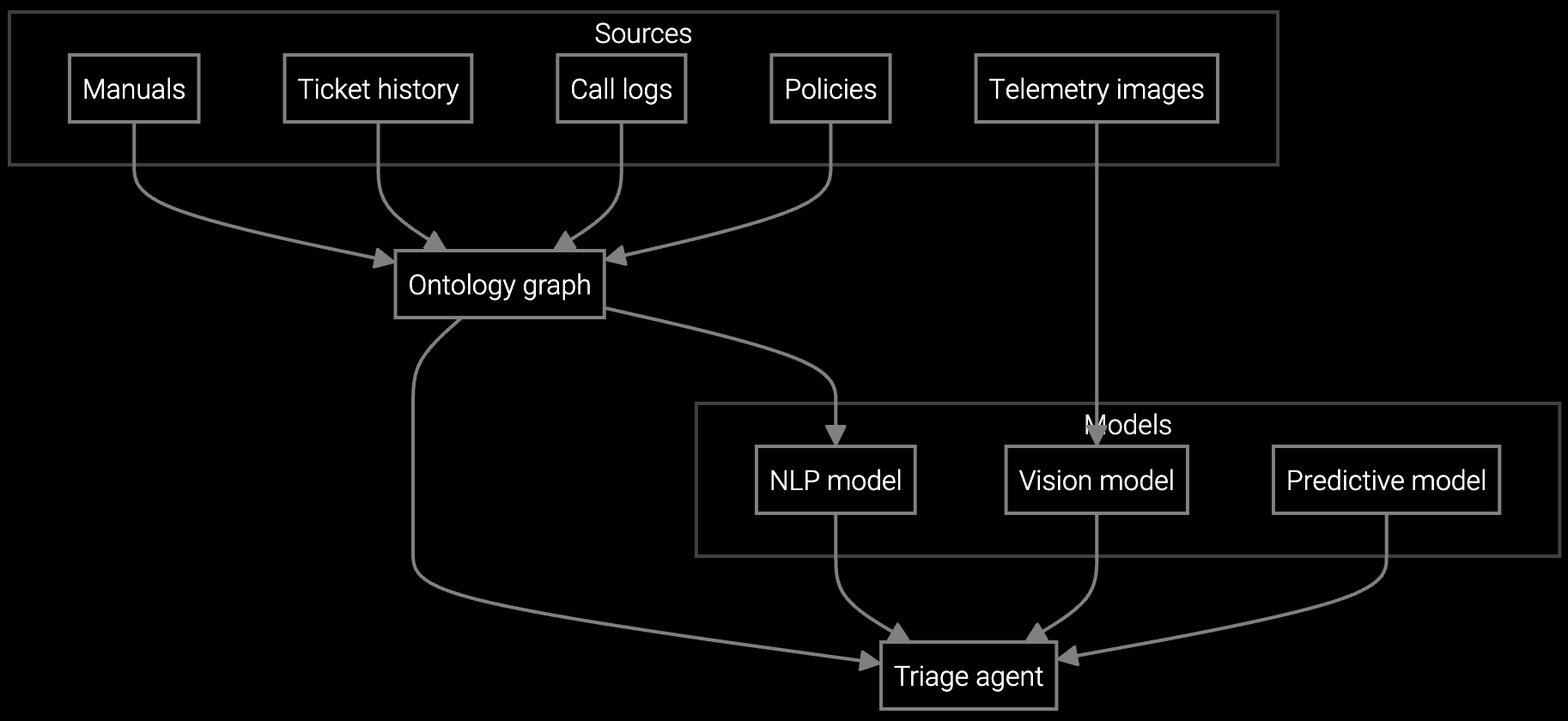
Autonomous case classification analyzes IPMI alerts, correlates thermal and power telemetry, and routes server issues to cooling specialists or compute teams with diagnostic context.
Instantly generates case summaries from emails, BMC logs, and chat transcripts so agents understand multi-rack issues without reading 50+ messages across scattered threads.

AI reads hyperscale operator emails, classifies failures by server SKU and firmware version, and drafts responses using historical resolution data and internal runbooks.
Data center OEMs serve customers who measure downtime in dollars per second and expect SLAs above 99.99%. Your agents handle server failures, storage anomalies, cooling alerts, and power distribution issues—all requiring instant context from IPMI telemetry, firmware versions, and rack-level thermal maps. Building this AI internally means hiring ML engineers who understand both contact center workflows and BMC data formats, then maintaining models as you release new server SKUs quarterly.
An API-first platform lets you start with out-of-the-box case classification and knowledge retrieval, then layer in custom logic for RAID failure prediction or PUE anomaly detection. When hyperscale customers deploy new BIOS versions or custom cooling configurations, you write a Python connector to parse their telemetry format and feed it into existing models without re-architecting the entire stack. This approach balances speed for commodity workflows with control for differentiated IP.
Initial integration with platforms like Zendesk, ServiceNow, or Salesforce Service Cloud typically takes 6-8 weeks. The platform provides pre-built connectors for common ticketing systems and exposes REST APIs for custom integrations. Most data center OEMs start with read-only case ingestion, then add write-back capabilities for auto-populated responses and routing decisions once they validate model accuracy.
Yes. Bruviti's Python SDK lets you write custom data parsers for IPMI logs, syslog streams, or proprietary BMC formats. You can fine-tune pre-trained models on your historical case data or train new classifiers from scratch if your failure taxonomy differs significantly from standard patterns. All training happens in your environment, so telemetry data never leaves your VPC or on-premises deployment.
The platform uses open data formats (JSON, Parquet) and standard protocols (REST, gRPC). All models can be exported in ONNX format for deployment outside the platform. You own all trained weights and can migrate to self-hosted inference if needed. Because integrations use your code via SDKs rather than proprietary connectors, switching costs are limited to rewriting API calls, not rebuilding entire workflows.
Start with pre-built capabilities for common workflows—email triage, knowledge search, case summarization—to demonstrate ROI within the first quarter. Once you prove value, allocate engineering time to custom extensions: parsers for specific telemetry streams, integrations with internal dashboards, or retraining classifiers on niche failure modes. This phased approach avoids the all-or-nothing risk of full custom builds while preserving flexibility for differentiated features.
Building equivalent AI capabilities internally typically costs 3-5 full-time ML engineers over 18-24 months, plus ongoing retraining and infrastructure costs. Platform licensing eliminates most build costs and provides continuous model updates as new equipment and failure modes emerge. Total cost depends on case volume, but most data center OEMs see breakeven within 12 months when factoring in reduced agent handle time and faster time-to-resolution for hyperscale customers.

Transforming appliance support with AI-powered resolution.

Understanding and optimizing the issue resolution curve.

Vision AI solutions for EV charging support.
See how API-first architecture delivers speed without lock-in for data center service operations.
Talk to an Architect